I Machine learning 1 Levenshtein distance II Modern Standard Arabic 1 Applications 1.1 Stem Counter 1.2 MorphoSyntactic Processor 1.3 Summarizer 1.4 Key Words Extractor 1.5 Moajam Moaassir 1.6 Moajam Tafaoli 1.7 Stop-words analyzer 2 Morphology 2.1 Morphological analyzer 2.2 Stemmer 2.3 Lemmatizer 3 Syntax 3.1 Parser 3.2 POS Tagger 4 Util 4.1 Normalization 4.2 Sentence splitter 4.3 Tokenization 4.4 Transliteration 4.5 Benchmark 4.5.1 Morphological analysers 4.5.2 Stemmers 4.6 Stop-Words 4.7 Pattern Detection 5 Resources 5.1 Alphabets lexicon 5.2 Clitics lexicon 5.3 Particles lexicon 5.4 CALEM lexicon 5.5 Contemporary dictionary 5.6 Interactive dictionary III Moroccan Arabic 1 Resources 1.1 MADED lexicon 1.2 Moralex lexicon
I. Machine learning
These examples illustrate the use of SAFAR ML APIs.
1. Levenshtein distance
These examples illustrate the use of SAFAR Levenshtein distance APIs.
The Levenshtein distance between two strings is defined as the minimum number of edits needed to transform one string into the other.
package safar.test;
public class LD {
public static void main(final String[] args) {
/*
Use LevenshteinFactory class to get all available implementations.
For example, to get Apache implementation, use: getApacheImplementation();
*/
ILevenshtein safarLevFactory = LevenshteinFactory.getSAFARImplementation();
// Compute de distance between two words
int safarLev = safarLevFactory.getLevenshtein("بَعْدِهِ", "بَعُدَ");
// display the result
System.out.println("Levenshtein distance is : " + safarLev);
}
}
Example of results:
Levenshtein distance is : 4
II. Modern Standard Arabic
These examples illustrate the use of SAFAR MSA APIs.
1. Applications
These examples illustrate the use of SAFAR APIs in some applications.
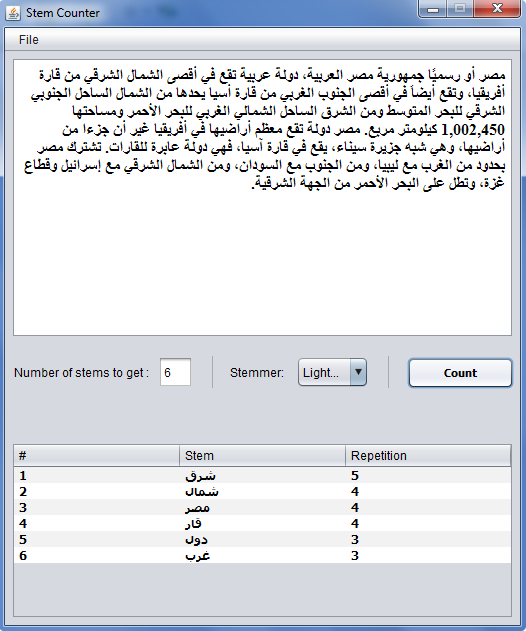
1.1 Stem Counter
The Stem Counter is an application that returns the most repeated stems in a text. The application gets stems using the stemmers implementations available in SAFAR plateform.
package safar.application.stemcounter;
public class StemCounterConsole {
public static void main(final String[] args) {
// Number of results to show
final int topX = 5;
// Text to process
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر "
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Execute the StemCounter application
StemCounter.launchConsole(text, topX);
}
}
Example of results:
شرق : 5 شمال : 4 مصر : 4 قار : 4 دول : 3
You can also use the GUI version of this application by calling the “launchGUI” method of the “StemCounter” class. The GUI allows users to specify the stemmer to use:
package safar.application.stemcounter;
public class StemCounterGUI {
public static void main(final String[] args) {
// Launch the GUI version of the Stem Counter
StemCounter.launchGUI();
}
}
The GUI version of the Stem Counter:
1.2 MorphoSyntactic Processor application
The MorphoSyntactic Processor is a GUI application that parses a sentence and analyzes its words. Use the following code to launch the application:
package safar.application.morphosyntactic_processor;
public class MorphoSyntacticProcessorGUI {
public static void main(final String[] args) {
// Launch the GUI
MorphoSyntacticProcessor.launchGUI();
}
}

1.3 Summarizer application
The Summarizer application extracts the most important sentence in a text. Use the following code to launch the application:
package safar.application.summarizer;
import safar.modern_standard_arabic.application.summarization.SummarizerFrame;
public class SummarizerGUI {
public static void main(final String[] args) {
// Launch the GUI
SummarizerFrame.launchGUI();
}
}

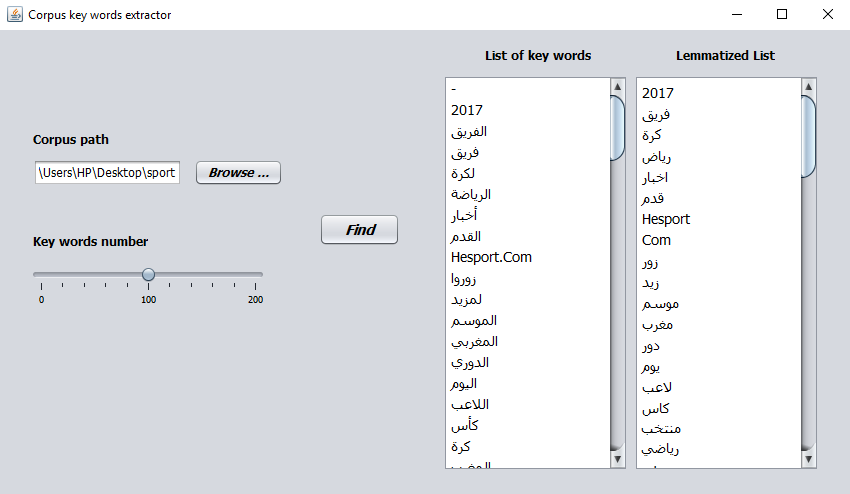
1.4 Key Words Extractor
The Key Words Extractor application extracts the most important key words in a corpus. Use the following code to launch the application:
package safar.application.kWE;
import safar.modern_standard_arabic.application.key_words_extractor.KWE;
public class KWEGUI {
public static void main(final String[] args) {
// Launch the GUI
KWE.main(args);
}
}
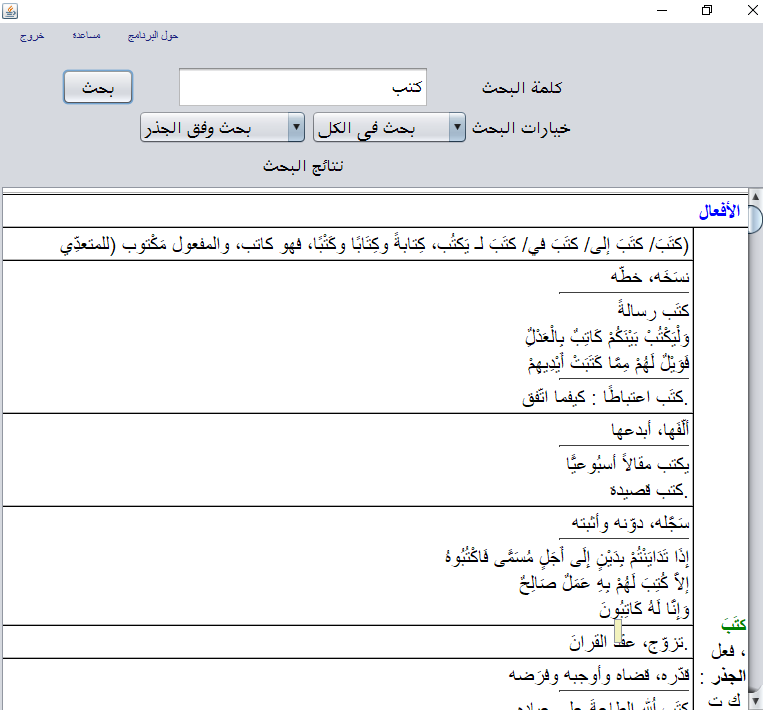
1.5 Moajam Moaassir
The moajam Moaassir application is a Moaassir lexicon search engine. Use the following code to launch the application:
package safar.application.moaassir;
import safar.modern_standard_arabic.application.moajam_moaassir.SForm;
public class MoaassirGUI {
public static void main(final String[] args) {
// Launch the GUI
SForm.launchGUI();
}
}
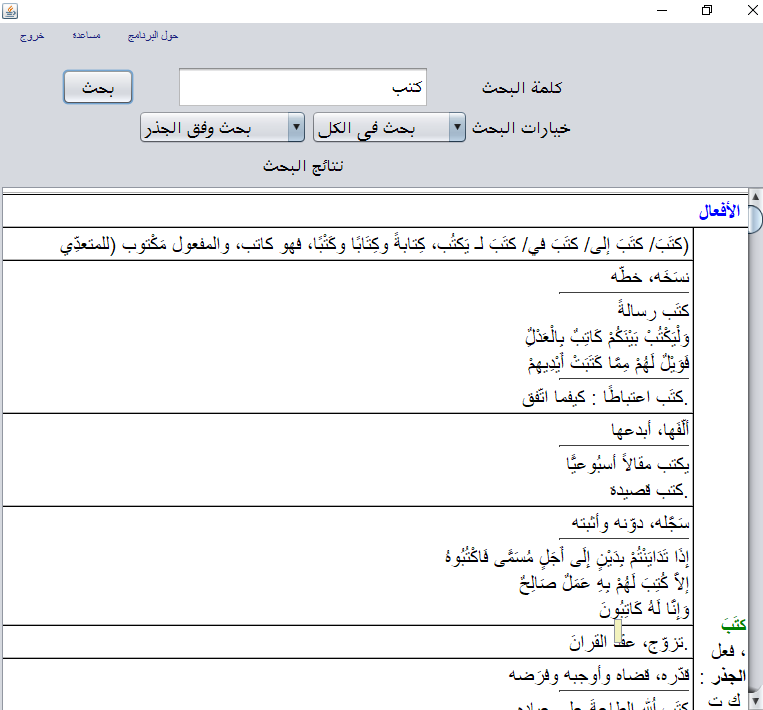
1.6 Moajam Tafaoli
The moajam Moaassir application is a Tafaoli lexicon search engine. Use the following code to launch the application:
package safar.application.tafaoli;
import safar.modern_standard_arabic.application.moajam_tafaoli.SForm;
public class TafaoliGUI {
public static void main(final String[] args) {
// Launch the GUI
SForm.launchGUI();
}
}
1.7 Stop-words analyzer
TheStop-words analyzer application is a contextual Stop-words detection tool.
package safar.test;
import safar.modern_standard_arabic.application.stopwords_analyzer.factory.SWAnalyserFactory;
import safar.modern_standard_arabic.application.stopwords_analyzer.interfaces.ISWAnalyserService;
public class TafaoliGUI {
public static void main(final String[] args) {
// Get Stop-words analyzer implementation
ISWAnalyserService SWA = SWAnalyserFactory.getSWAnalyserImplementation();
// analyze
Map results = SWA.analyze(txt);
results.entrySet().forEach((entry) -> {
System.out.print(" " + entry.getValue());
});
}
}
Results:
تطلب الاشتراك فِي إحدى الخدمات الَّتي يقدمها الموقع، مِثْل البريد الالكتروني أَوْ التسجيل فِي خدمة سؤال وجواب أَوْ المشاركة فِي الاختبارات المتاحة، فَقَدْ نطلب تقديم بيانات شخصية، مِثْل الاسم وعنوان البريد الالكتروني وتاريخ الميلاد. يستخدم الموقع أيضا ملفات تعريف الارتباط cookies، وَهِي عبارة عَنْ بيانات محدودة عَنْ تفضيلات المستخدمين المرتبطيم، وَهَذِه البيانات تساعد الموقع عَلَى تلبية احتياجات مستخدميها. بشكل مشابه يقوم موقع الموقع أيضا بتسجيل عنوان الـ IP، وَهُو عبارة عَنْ رقم يمكن أَنْ يحدد كُل جهاز كمبيوتر يستخدم شبكة الانترنت. نستخدم برامج تحليلية لمتابعة ملفات الارتباط cookies وعناوين الـ IP بهدف التعرف عَلَى احتياجات المستخدمين. وَلاَ تستخدم هَذِه المعلومات لتجميع ملفات شخصية عَنْكُم.
2. Morphology
These examples illustrate the use of SAFAR APIs for the morphology Layer (Morphological Anlyzers and stemmers) with several implementations.
2.1 Morphological analyzer
A morphological analyzer identifies the structure of a given language morphemes and other linguistic units such as root, stem, affixes, parts of speech etc. SAFAR implements several morphological analyzers.
In order to use a morphological analyzer implementation in SAFAR, you should include the appropriate .jar in you classpath (For example: to use Alkhalil analyzer, you should include AlKhalil.jar). All libraries are available in the lib directory of SAFAR
Example1: Analyze a text with Alkhalil morphological analyzer and save analysis results as XML
package safar.basic.morphology.analyzer;
import java.io.File;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.analyzer.factory.MorphologyAnalyzerFactory;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.analyzer.interfaces.IMorphologyAnalyzer;
public class AnalyzersTests1 {
public static void main(final String[] args) {
/*
Use MorphologyAnalyzerFactory class to get all available analyzers
implementations. For example, to get Alkhalil analyzer implementation, use:
*/
IMorphologyAnalyzer analyzer = MorphologyAnalyzerFactory.getAlkhalilImplementation();
// Text to be analyzed
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
/*
Analyze the text with the specified analyzer and save results as XML.
There are many "analyze" overloaded methods, use the method that suits your needs.
*/
analyzer.analyze(text, new File("analysis_results.xml"));
}
}
Example of morphology analysis results (using Alkhalil implementation):

For an advanced use, you can call an overloaded “analyze” method that returns a list of WordMorphologyAnalyis objects containing all morphological analysis:
Example2: Analyze a text with Alkhalil morphological analyzer and get results as list of WordMorphologyAnalyis objects
package safar.basic.morphology.analyzer;
import java.util.List;
import safar.modern_standard_arabic.basic.morphology.analyzer.factory.MorphologyAnalyzerFactory;
import safar.modern_standard_arabic.basic.morphology.analyzer.interfaces.IMorphologyAnalyzer;
import safar.modern_standard_arabic.basic.morphology.analyzer.model.MorphologyAnalysis;
import safar.modern_standard_arabic.basic.morphology.analyzer.model.NounMorphologyAnalysis;
import safar.modern_standard_arabic.basic.morphology.analyzer.model.ParticleMorphologyAnalysis;
import safar.modern_standard_arabic.basic.morphology.analyzer.model.VerbMorphologyAnalysis;
import safar.modern_standard_arabic.basic.morphology.analyzer.model.WordMorphologyAnalysis;
public class AnalyzersTests2 {
public static void main(final String[] args) {
// Get Alkhalil morphological analyzer implementation
IMorphologyAnalyzer analyzer = MorphologyAnalyzerFactory.getAlkhalilImplementation();
/*
Use MorphologyAnalyzerFactory class to get all available analyzers
implementations. For example, to get BAMA analyzer implementation, use:
IMorphologyAnalyzer analyzer = MorphologyAnalyzerFactory.getBAMAImplementation();
*/
// Text to be analyzed
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Analyze the text with the specified analyzer and get results as WordMorphologyAnalyis objects
List wordMorphologyAnalysis = analyzer.analyze(text);
// You can now manipulate the list of results
for (WordMorphologyAnalysis wordAnalysis : wordMorphologyAnalysis) {
// Print the current word
System.out.println("Original word: " + wordAnalysis.getNormalizedWord());
System.out.println("-----");
// Get the list of morphological analysis for the current word
List listOfAnalysis = wordAnalysis.getStandardAnalysisList();
// Print all analysis
for (MorphologyAnalysis analysis : listOfAnalysis) {
// Print the unvowled form of the stem for the current analysis.
System.out.println("Stem: " + analysis.getStem().getUnvoweledForm());
// Print the type of the word for the current analysis
System.out.println("Type: " + analysis.getType());
// Test if the current analysis concerns a verb
if (analysis.isVerb()) {
// Cast the current analysis to VerbMorphologyAnalysis object.
VerbMorphologyAnalysis verbAnalysis = (VerbMorphologyAnalysis) analysis;
System.out.println("Root: " + verbAnalysis.getRoot());
System.out.println("Pattern: " + verbAnalysis.getPattern());
System.out.println("POS: " + verbAnalysis.getPos());
// You can get ohter information about the verb...
} else if (analysis.isNoun()) {
// Test if the current analysis concerns a noun
// Cast the current analysis to NounMorphologyAnalysis object
NounMorphologyAnalysis nounAnalysis = (NounMorphologyAnalysis) analysis;
System.out.println("Root: " + nounAnalysis.getRoot());
System.out.println("Pattern: " + nounAnalysis.getPattern());
System.out.println("POS: " + nounAnalysis.getPos());
// You can get ohter information about the noun...
} else if (analysis.isParticle()) {
// Test if the current analysis concerns a particle
// Cast the current analysis to ParticleMorphologyAnalysis object.
ParticleMorphologyAnalysis particleAnalysis = (ParticleMorphologyAnalysis) analysis;
System.out.println("POS: " + particleAnalysis.getPos());
}
System.out.println("-----");
}
System.out.println("==============");
}
}
}
There are also several other overloaded “analyze” methods that you can use to cover more possibilities, here is the complete list:
1 – “analyze” methods that save analysis results as XML File:
void analyze(String text, File outputFile);
void analyze(String text, File outputFile, String outputLanguage);
void analyze(File inputFile, File outputFile);
void analyze(File inputFile, File outputFile, String inputEncoding);
void analyze(File inputFile, File outputFile, String inputEncoding, String outputLanguage);
2 – “analyze” methods that return analysis results as WordMorphologyAnalyis objects:
List<WordMorphologyAnalysis> analyze(String text);
List<WordMorphologyAnalysis> analyze(File inputFile);
List<WordMorphologyAnalysis> analyze(File inputFile, String inputEncoding);
Where:
| text | The text to be analyzed |
| inputFile | The File to be analyzed |
| outputFile | The File in which results will be saved |
| inputEncoding | The encoding of the inputFile. If not specified, UTF-8 will be used by default. Use the class Encoding to get all available encodings. e.g: to use UTF-8, call Encoding.UTF_8 |
| outputLanguage | The outputLanguage parameter allows you to save the XML File (containing results) either in English or in Arabic. Use the class “Language” to get all available languages. e.g: to use Arabic as output language, call Language.ARABIC |
2.2 Stemmer
Stemming is the process of removing affixes from a word and reducing it to the root (some stemmers reduce the word to the stem instead of the root).
In order to use a stemmer implementation in SAFAR, you should include the appropriate .jar in you classpath (For example: to use Khoja stemmer, you should include khojastemmer.jar). All libraries are available in the lib directory of SAFAR
Example1: Stem a text with Khoja stemmer and save stemming results as XML
package safar.basic.morphology.stemmer;
import java.io.File;
import safar.modern_standard_arabic.basic.morphology.stemmer.factory.StemmerFactory;
import safar.modern_standard_arabic.basic.morphology.stemmer.interfaces.IStemmer;
public class StemmerTests1 {
public static void main(final String[] args) {
// Get Khoja stemmer implementation
IStemmer stemmer = StemmerFactory.getKhojaImplementation();
/*
Use StemmerFactory class to get all available stemmers implementations.
For example, to get Light10 stemmer implementation, use:
IStemmer stemmer = StemmerFactory.getLight10Implementation();
*/
// Text to be stemmed
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Stem the text and save stemming results as XML
stemmer.stem(text, new File("stemming_results.xml"));
}
}
Example of the stemming results (using Khoja stemmer):

For an advanced use, you can call an overloaded “stem” method that returns a list of WordStemmerAnalysis objects containing all stemming results:
Example2: Stem a text with Khoja stemmer and get results as list of WordStemmerAnalysis objects
package safar.basic.morphology.stemmer;
import java.util.List;
import safar.modern_standard_arabic.basic.morphology.stemmer.factory.StemmerFactory;
import safar.modern_standard_arabic.basic.morphology.stemmer.interfaces.IStemmer;
import safar.modern_standard_arabic.basic.morphology.stemmer.model.StemmerAnalysis;
import safar.modern_standard_arabic.basic.morphology.stemmer.model.WordStemmerAnalysis;
public class StemmerTests2 {
public static void main(final String[] args) {
// Get Khoja stemmer implementation
IStemmer stemmer = StemmerFactory.getKhojaImplementation();
/*
Use StemmerFactory class to get all available stemmers
implementations. For example, to get Light10 stemmer implementation, use:
IStemmer stemmer = StemmerFactory.getLight10Implementation();
*/
// Text to be stemmed
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Stem the text and get results as WordStemmerAnalysis objects
List analysis = stemmer.stem(text);
// You can now manipulate the list of results
for (WordStemmerAnalysis wordAnalysis: analysis) {
// Print the original word before stemming
System.out.println("Original word: " + wordAnalysis.getWord());
// Get the list of possible stems for the current word
List listOfStems = wordAnalysis.getListStemmerAnalysis();
// Print the list of possible stems for the current word
for (StemmerAnalysis stem: listOfStems) {
// Print the stem
System.out.println("Stem: " + stem.getMorpheme());
// Print the type of the stem (Stem or Root)
System.out.println("Type: " + stem.getType());
}
}
}
}
There are also several other overloaded “stem” methods that you can use to cover more possibilities, here is the complete list:
1 – “stem” methods that save stemming results as XML File:
void stem(String text, File outputFile);
void stem(String text, File outputFile, String outputLanguage);
void stem(File inputFile, File outputFile);
void stem(File inputFile, File outputFile, String inputEncoding);
void stem(File inputFile, File outputFile, String inputEncoding, String outputLanguage);
2 – “stem” methods that return stemming results as WordStemmerAnalysis objects:
List<WordStemmerAnalysis> stem(String text);
List<WordStemmerAnalysis> stem(File inputFile);
List<WordStemmerAnalysis> stem(File inputFile, String inputEncoding);
Where:
| text | The text to be stemmed |
| inputFile | The File to be stemmed |
| outputFile | The File in which results will be saved |
| inputEncoding | The encoding of the inputFile. If not specified, UTF-8 will be used by default. Use the class Encoding to get all available encodings. e.g: to use ISO-8859-6, call Encoding.ISO_8859_6 |
| outputLanguage | The outputLanguage parameter allows you to save the XML File (containing results) either in English or in Arabic. Use the class “Language” to get all available languages. e.g: to use Arabic as output language, call Language.ARABIC |
2.3 Lemmatizer
Lemmatization is the process of reducing a word to its lemma. SAFAR plateform implements AlKalil, Farasa and SAFAR Lemmatizers
In order to use a lemmatizer implementation in SAFAR, you should include the SAFAR.jar in you classpath
Example: Lemmatize a text with SAFAR lemmatizer and get results as list of objects
package safar.lemmatization;
import java.util.List;
import org.apache.commons.io.FileUtils;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.lemmatizer.factory.LemmatizerFactory;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.lemmatizer.interfaces.ILemmatizer;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.lemmatizer.model.LemmatizerAnalysis;
import safar.modern_standard_arabic.modern_standard_arabic.basic.morphology.lemmatizer.model.WordLemmatizerAnalysis;
public class LemmatizerTests {
public static void main(final String[] args) {
// Get SAFAR lemmatizer implementation
ILemmatizer theLemmatizer = LemmatizerFactory.getSAFARImplementation();
/*
Use lemmatizerFactory class to get all available lemmatizers
implementations. For example, to get FARASA lemmatizer implementation, use:
ILemmatizer lemmatizerFactory = LemmatizerFactory.getFARASAImplementation();
And to get Alkhalil lemmatizer implementation, use:
ILemmatizer lemmatizerFactory = LemmatizerFactory.getALKALILImplementation();
*/
// Text to be lemmatized
String text = "تَتَفَتَّحُ الوُرُودُ فِي الرَّبِيعِ لا الخَرِيفِ";
// lemmatize the text and get results as WordLemmatizerAnalysis objects
List analysis = theLemmatizer.lemmatize(text);
// You can now manipulate the list of results
for (WordLemmatizerAnalysis wordAnalysis : analysis) {
// Print the list of all possible lemmas for the current word (we quote that the best one according to the context is the first)
for (LemmatizerAnalysis lemma : wordAnalysis.getStandardAnalysisList()) {
// Print the lemma
System.out.println("lemma: " + lemma.getLemma());
}
}
}
}
N.B.: Due to lexicons loading, the lemmatizer takes time with small texts. While for large texts, the execution time remains very good.
3. Syntax
These examples illustrate the use of SAFAR APIs for Syntax classes.
3.1 Parser
In order to use a syntactic parser implementation in SAFAR, you should include the appropriate .jar in you classpath (For example: to use StarnfordParser, you should include stanford-parser.jar and stanford-parser-3.2.0-models.jar). All libraries are available in the lib directory of SAFAR
Example1: Parse a text with StarnfordParser and save parsing results as XML
package safar.basic.syntax;
import common.constants.Parser;
import common.constants.ParserOutput;
import java.io.File;
import safar.modern_standard_arabic.basic.syntax.parser.factory.ParserFactory;
import safar.modern_standard_arabic.basic.syntax.parser.interfaces.IParser;
public abstract class SyntaxTests1 {
public static void main(final String[] args) throws Exception {
// Get a parser implementation (you can use STANFORD_PARSER, ATKS_PARSER or FARASA_PARSER )
IParser parser = ParserFactory.getImplementation(Parser.STANFORD_PARSER);
// Sentence to be parsed
String sentence = "دخل الولد إلى القسم";
// Set the output File
File outputFile = new File("ParsingResults.txt");
// Parse the sentence and save results as xml File
parser.parse(sentence, outputFile, ParserOutput.XML_TREE);
}
}
Example of the parsing results (using StanfordParser):

You can use the
ParserOutput class specify what results should be returned: XML_TREE, SIMPLE_TREE, XML_TREE_WITH_DEPENDENCIES or DEPENDENCIES.For an advanced use, you can call an overloaded “parse” method that returns a list of SentenceParsingAnalysis objects containing all paring results:
Example2: Parse a sentence with StanfordParser and get results as list of SentenceParsingAnalysis objects
package safar.basic.syntax;
import common.constants.Parser;
import java.util.ArrayList;
import safar.modern_standard_arabic.basic.syntax.parser.factory.ParserFactory;
import safar.modern_standard_arabic.basic.syntax.parser.interfaces.IParser;
import safar.modern_standard_arabic.basic.syntax.parser.model.Dependency;
import safar.modern_standard_arabic.basic.syntax.parser.model.OneParsingAnalysis;
import safar.modern_standard_arabic.basic.syntax.parser.model.SentenceParsingAnalysis;
public abstract class SyntaxTests2 {
public static void main(final String[] args) throws Exception {
// Get a parser implementation (you can use STANFORD_PARSER, ATKS_PARSER or FARASA_PARSER )
IParser parser = ParserFactory.getImplementation(Parser.STANFORD_PARSER);
// Sentence to be parsed
String sentence = "ونشر العدل من خلال فضاء مستقل";
// Parse the sentence and get results as SentenceParsingAnalysis object
SentenceParsingAnalysis parsed = parser.parse(sentence);
// Print dependencies
OneParsingAnalysis opa = parsed.getListOfParsinganalysis().get(0);
ArrayList dependecies = opa.getDependency();
for (Dependency d : dependecies) {
System.out.print("Relation " + d.getType());
System.out.print(" | Head: " + d.getHead().getValue());
System.out.println(" - Dependent: " + d.getDependent().getValue());
}
}
}
Example of the parsing results using StanfordParser (printing dependencies):

There are also several other overloaded “parse” methods that you can use to cover more possibilities.
3.2 POS Tagger
SAFAR plateform implements Farasa and SAFAR POS Taggers
Example: Tag a text with SAFAR and display results
package safar.basic.syntax;
import java.util.List;
import safar.modern_standard_arabic.basic.syntax.posTagger.factory.PosFactory;
import safar.modern_standard_arabic.basic.syntax.posTagger.interfaces.IPos;
import safar.modern_standard_arabic.basic.syntax.posTagger.model.WordPOSAnalysis;
public abstract class PosTagTests {
public static void main(final String[] args) throws Exception {
// Text to be tagged
String text = "نصف المغاربة"
+ " يعانون مشاكل نفسية . مغربي من بين اثنين لديه مشكل نفسي , هل تعرف ماذا يعني هذا ؟ أنا شخصيا"
+ " لا أعرف . إذا عرفت قل لي . أنا مغربي زائد أنت مغربي تساوي مغربيين . فمن منا المريض النفسي ومن منا السليم ؟ طبعا"
+ " ، أنا المريض .";
System.out.println("--------Tag the text------");
System.out.println(text + "\n");
// Factory instantiation and method call
IPos pos = PosFactory.getSafarLightPOSImplementation();
List wordPosAnalysis = pos.tag(text);
//Output the result
System.out.println("--------The tagger output------");
List posAnalysis = wordPosAnalysis;
for (int i = 0; i < posAnalysis.size(); i++) {
System.out.println("-----");
System.out.println("Original word: " + posAnalysis.get(i).getWord());
System.out.println("-----");
System.out.println("POS: " + posAnalysis.get(i).getTag());
}
}
}
Example of the tagging results (using Safar Light POS):
----- Original word: نصف ----- POS: N ----- Original word: المغاربة ----- POS: N ----- Original word: يعانون ----- POS: V ----- Original word: مشاكل ----- POS: N -----
4. Util
These examples illustrate the use of SAFAR APIs for util classes.
4.1 Normalization
Normalization is the process of deleting some elements from texts. These are mostly special characters, numbers, non-Arabic words, abbreviations and single letters. These elements increase the processing time of some programs such as morphological analyzers. SAFAR plateform proposes methods to do this task very easily.
Example1: Normalize a text with SAFAR using the default normalization. This consists of :- Deleting all non arabic letters.
- Deleting all special characters (kashida included).
- Deleting all words containing digits.
- Deleting all words composed of one letter.
package safar.util;
import safar.modern_standard_arabic.util.normalization.impl.SAFARNormalizer;
public class NormalizerTest {
public static void main(final String[] args) {
// Text to normalize
String text = "وستتنــــــافس طائرات "
+ "x777 "
+ "قرب بداية العقد المقبل مع طائرات "
+ "Airbus أيه350- 1000 "
+ "لإنشاء سوق محتملة لما لا يقل عن 2000 "
+ ".طائرة تقدر قيمتها ب خمسمائة مليار $ على مدار 20 عاما";
// Get SAFAR normalizer
SAFARNormalizer normalizer = new SAFARNormalizer();
// Normalize the text
String normalizedText = normalizer.normalize(text);
// Print the normalized text
System.out.println(normalizedText);
}
}
The result of executing the above program is the following normalized text:
وستتنافس طائرات قرب بداية العقد المقبل مع طائرات لإنشاء سوق محتملة لما لا يقل عن طائرة تقدر قيمتها خمسمائة مليار على مدار عاما
To be more flexible, SAFAR overload the "normalize" method to allow normalizing the Arabic text in different ways. While the default normalization method specify only the text to process, the overloaded method is specified with three parameters:String normalize (String text, String formOfNormalization, String otherCharsToDelete)
where:
| formOfNormalization | A String composed of concatenation of letters "a", "b", "c" and "d". a: to delete all special characters and non arabic letters (numbers are not concerned) b: to delete all words that are composed of digits only (numbers) c: to delete all words that are composed of both digits and letters or only digits d: to delete all words that are composed of only one letter. e.g: the "abcd" form will remove all elements mentioned above. The "c" form will remove every word containing a digit. If this parameter is an empty String, None of the above operations will be executed |
| otherCharsToDelete | Other individual characters to delete (separated with white spaces). |
These two additional parameters allows you to specify whatever you want to delete.
Example2: Normalize a text with SAFAR using the customized normalization method:
package safar.util;
import safar.modern_standard_arabic.util.normalization.impl.SAFARNormalizer;
public class NormalizerTest {
public static void main(final String[] args) {
// Text to normalize
String text = "وستتنــــــافس طائرات "
+ "x777 "
+ "قرب بداية العقد المقبل مع طائرات "
+ "Airbus أيه350- 1000 "
+ "لإنشاء سوق محتملة لما لا يقل عن 2000 "
+ ".طائرة تقدر قيمتها ب خمسمائة مليار $ على مدار 20 عاما";
// Get SAFAR normalizer
SAFARNormalizer normalizer = new SAFARNormalizer();
/*
Normalize the text.
The form "ad" means: Delete all special characters and non Arabic letters (numbers are not concerned)
and also delete all words that are composed of only one letter.
The String "$ x" means: In addition to what is deleted in the step above, delete also the caracter "$" and the letter "x".
*/
String normalizedText = normalizer.normalize(text, "ad", "$ x");
// Print de normalized text
System.out.println(normalizedText);
}
}
The result of this normalization is:
وستتنافس طائرات 777 قرب بداية العقد المقبل مع طائرات أيه350 1000 لإنشاء سوق محتملة لما لا يقل عن 2000 طائرة تقدر قيمتها خمسمائة مليار على مدار 20 عاما
If you deal with Files as input instead of Strings or if you want to save results as file, you can call other overloaded "normalize" methods. Here is the complete list of all overloaded methods concerning normalization:1 - "normalize" methods that save result as text File:
void normalize(String text, File outputFile);
void normalize(String text, File outputFile, String formOfNormalization, String otherCharsToDelete);
void normalize(File inputFile, String inputEncoding, File outputFile);
void normalize(File inputFile, String inputEncoding, File outputFile, String formOfNormalization, String otherCharsToDelete);
2 - "normalize" methods that return result as String:
String normalize(String text)
String normalize(String text, String formOfNormalization, String otherCharsToDelete)
String normalize(File inputFile, String inputEncoding)
String normalize(File inputFile, String inputEncoding, String formOfNormalization, String otherCharsToDelete)
where:
| text | The text to be normalized. |
| inputFile | The File to be normalized. |
| inputEncoding | The encoding of the inputFile. Use the class "Encoding" to get all available encodings. e.g: to use UTF-8, call: Encoding.UTF_8 |
| outputFile | The File in which result will be saved |
| formOfNormalization | The same as explained above. |
| otherCharsToDelete | The same as explained above. |
4.2 Sentence splitter
This process splits a text into sentences. SAFAR proposes several methods to do this.
Example1: Split a text into sentences and get the result as an array of Strings - Default sentence splitter:
package safar.util;
import safar.modern_standard_arabic.util.splitting.impl.SAFARSentenceSplitter;
public class SentenceSplitterTest {
public static void main(final String[] args) {
// Text to split
String text = " ملخص شروط صحة الصلاة من كتاب: تمام المنة."
+ " - العِلم بدخُول وقتِ الصلاة."
+ " - الطهارة مِن الحَدَث الأصغر والأكبر."
+ " - طهارة الثوْب والبَدَن والمكان مِن النجاسة."
+ " - سَتر العَوْرَة."
+ " - استقبال القِبْلَة."
+ " صاحب الكتاب هو: ذ. رامي حنفي محمود.";
// Get SAFAR Sentence splitter implementation
SAFARSentenceSplitter sentenceSplitter = new SAFARSentenceSplitter();
// Split the text into sentences and get the result as an Array of Strings containing all sentences
// The dot "." is the default delimiter of sentences
String[] sentences = sentenceSplitter.split(text);
// Print the sentences
for(String sentence: sentences){
System.out.println(sentence);
}
}
}
ملخص شروط صحة الصلاة من كتاب: تمام المنة.
أ.
العِلم بدخُول وقتِ الصلاة! ب.
الطهارة مِن الحَدَث الأصغر والأكبر.
ت.
طهارة الثوْب والبَدَن والمكان مِن النجاسة.
ث.
سَتر العَوْرَة.
خ.
استقبال القِبْلَة.
صاحب الكتاب هو: ذ.
رامي حنفي محمود.
The "split" method used above considers the dot "." as default delimiter of sentences. This method have two disadvantages: the first one is that you can not specify another delimiter than the dot (for example ! ?). The second one is that if your text contains special words which have the dot "." as part of them (e.g: .أ ), their will be considered as sentences. But this method still valid for a lot of texts which not have special words.
To resolve these problems, SAFAR overloads the "split" method in order to customize the process of splitting. Here is the complete list of overloaded methods:
1 - "split" methods that save sentences as XML File:
void split(String text, File outputFile);
void split(String text, String delimiters, String specialCases, File outputFile);
void split(String text, String delimiters, String specialCases, File outputFile, String outputLanguage);
void split(File inputFile, String inputEncoding, File outputFile);
void split(File inputFile, String delimiters, String specialCases, File outputFile);
void split(File inputFile, String delimiters, String specialCases, File outputFile, String inputEncoding);
void split(File inputFile, String delimiters, String specialCases, File outputFile, String inputEncoding, String outputLanguage);
2 - "split" methods that return sentences as an Array of Strings:
String[] split(String text);
String[] split(String text, String delimiters, String specialCases);
String[] split(File inputFile);
String[] split(File inputFile, String delimiters, String specialCases);
String[] split(File inputFile, String delimiters, String specialCases, String inputEncoding);
Where:
| text | The text to be splitted into sentences |
| inputFile | The File to be splitted into sentences |
| outputFile | The File in which sentences will be saved |
| inputEncoding | The encoding of the inputFile. If not specified, UTF-8 will be used by default. Use the class Encoding to get all available encodings. e.g: to use UTF-8, call Encoding.UTF_8 |
| delimiters | A String containing all punctuation characters ending a sentence, separated with white spaces. e.g ". ! ?" |
| specialCases | A String containing all special words which have some delimiters as part of them and which are not supposed to be an end of sentence (separated with white spaces). e.g ".1 .2 .أ" |
| outputLanguage | The outputLanguage parameter allows you to save the XML File (containing results) either in English or in Arabic. Use the class "Language" to get all available languages. e.g: to use Arabic as output language, call Language.ARABIC |
Example2: Split a text into sentences and get the result as an array of Strings - customized sentence splitter:
package safar.util;
import safar.modern_standard_arabic.util.splitting.impl.SAFARSentenceSplitter;
public class SentenceSplitterTest {
public static void main(final String[] args) {
// Text to split
String text = " ملخص شروط صحة الصلاة من كتاب: تمام المنة."
+ " - العِلم بدخُول وقتِ الصلاة."
+ " - الطهارة مِن الحَدَث الأصغر والأكبر."
+ " - طهارة الثوْب والبَدَن والمكان مِن النجاسة."
+ " - سَتر العَوْرَة."
+ " - استقبال القِبْلَة."
+ " صاحب الكتاب هو: ذ. رامي حنفي محمود.";
// Get SAFAR Sentence splitter implementation
SAFARSentenceSplitter sentenceSplitter = new SAFARSentenceSplitter();
// Split the text into sentences and get the result as an Array of Strings containing all sentences
// The characters "." and "!" are used to delimite sentences. Special words for this case are ".أ. خ. ب. ت. ث. ذ"
String[] sentences = sentenceSplitter.split(text, ". !", ".أ. خ. ب. ت. ث. ذ");
// Print the sentences
for(String sentence: sentences){
System.out.println(sentence);
}
}
}
The result of this splitting is:
ملخص شروط صحة الصلاة من كتاب: تمام المنة.
أ. العِلم بدخُول وقتِ الصلاة!
ب. الطهارة مِن الحَدَث الأصغر والأكبر.
ت. طهارة الثوْب والبَدَن والمكان مِن النجاسة.
ث. سَتر العَوْرَة.
خ. استقبال القِبْلَة.
صاحب الكتاب هو: ذ. رامي حنفي محمود.
Example3: Split a text into sentences and save results as XML File (using Arabic as output language):
package safar.util;
import common.constants.Language;
import java.io.File;
import java.io.IOException;
import safar.modern_standard_arabic.util.splitting.impl.SAFARSentenceSplitter;
public class SentenceSplitterTest {
public static void main(final String[] args) throws IOException {
// Text to split
String text = " ملخص شروط صحة الصلاة من كتاب: تمام المنة."
+ " - العِلم بدخُول وقتِ الصلاة."
+ " - الطهارة مِن الحَدَث الأصغر والأكبر."
+ " - طهارة الثوْب والبَدَن والمكان مِن النجاسة."
+ " - سَتر العَوْرَة."
+ " - استقبال القِبْلَة."
+ " صاحب الكتاب هو: ذ. رامي حنفي محمود.";
// Get SAFAR Sentence splitter implementation
SAFARSentenceSplitter sentenceSplitter = new SAFARSentenceSplitter();
// Split the text into sentences and save results in sentences.xml File
// The characters "." and "!" are used to delimite sentences. Special words for this case are ".أ. خ. ب. ت. ث. ذ"
// The output language used to present results is Arabic
sentenceSplitter.split(text, ". !", ".أ. خ. ب. ت. ث. ذ", new File("sentences.xml"), Language.ARABIC);
}
}
Example of saved sentences:

4.3 Tokenization
We define tokenization as the process of splitting a text into elements (words) which are separated with whitespaces. SAFAR Plateform proposes several methods allowing the tokenization.
Example1: Tokenize a text and save tokens as XML File:
package safar.util;
import java.io.File;
import safar.modern_standard_arabic.util.tokenization.impl.SAFARTokenizer;
public class TokenizerTest {
public static void main(final String[] args) throws Exception {
// Text to tokenize
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Get SAFAR tokenizer implementation
SAFARTokenizer tokenizer = new SAFARTokenizer();
// Tokenize the text and save tokens in "tokens.xml" file
tokenizer.tokenize(text, new File("tokens.xml"));
}
}
Example of the result after being saved as XML file:

Example2: Tokenize a text and get an Array of Strings containing all tokens:
package safar.util;
import safar.modern_standard_arabic.util.tokenization.impl.SAFARTokenizer;
public class TokenizerTest {
public static void main(final String[] args) {
// Text to tokenize
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر"
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Get SAFAR tokenizer implementation
SAFARTokenizer tokenizer = new SAFARTokenizer();
// Tokenize the text and get an Array of tokens
String[] tokens = tokenizer.tokenize(text);
}
}
There are also several other overloaded "tokenize" methods that you can use to cover more possibilities, here is the complete list:
1 - "tokenize" methods that save tokens as XML File:
void tokenize(String text, File outputFile);
void tokenize(String text, File outputFile, boolean withUniqueTokens, String outputLanguage);
void tokenize(File inputFile, File outputFile);
void tokenize(File inputFile, File outputFile, String inputEncoding, boolean withUniqueTokens, String outputLanguage);
2 - "tokenize" methods that return tokens as an Array of Strings:
String[] tokenize(String text);
String[] tokenize(String text, boolean withUniqueTokens);
String[] tokenize(File inputFile);
String[] tokenize(File inputFile, String inputEncoding, boolean withUniqueTokens);
Where:
| text | The text to be tokenized |
| inputFile | The File to be tokenized |
| outputFile | The File in which tokens will be saved |
| inputEncoding | The encoding of the inputFile. If not specified, UTF-8 will be used by default. Use the class Encoding to get all available encodings. e.g: to use UTF-8, call Encoding.UTF_8 |
| withUniqueTokens | If set to true, there will be not duplicate tokens in results. If set to false, all tokens will be present in results even duplicated. |
| outputLanguage | The outputLanguage parameter allows you to save the XML File (containing tokens) either in English or in Arabic. Use the class "Language" to get all available languages. e.g: to use Arabic as output language, call Language.ARABIC |
4.4 Transliteration
Transliteration is the process of writing a language by using letters of another language. SAFAR proposes methods to do this:
Example1: Get a Buckwalter transliteration from an Arabic text:
package safar.util;
import common.constants.Transliteration;
import safar.modern_standard_arabic.util.transliteration.impl.SAFARTransliterator;
public abstract class TransliterationTest {
public static void main(final String[] args) {
// Text to be transliterated
String text = "مصر أو رسميًا جمهورية مصر العربية، دولة عربية"
+ " تقع في أقصى الشمال الشرقي من قارة أفريقيا،"
+ " وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا"
+ " يحدها من الشمال الساحل الجنوبي الشرقي للبحر"
+ " المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر "
+ " ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع"
+ " معظم أراضيها في أفريقيا غير أن جزءا من أراضيها،"
+ " وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي"
+ " دولة عابرة للقارات. تشترك مصر بحدود من الغرب"
+ " مع ليبيا، ومن الجنوب مع السودان، ومن الشمال "
+ " الشرقي مع إسرائيل وقطاع غزة، وتطل على"
+ " البحر الأحمر من الجهة الشرقية.";
// Get SAFAR transliterator
SAFARTransliterator transliterator = new SAFARTransliterator();
// Transliterate the text using Buckwalter encoding
String result = transliterator.transliterateArabicToLatin(text, Transliteration.BUCKWALTER);
// Print the result of transliteration
System.out.println(result);
}
}
The result of this transliteration is:
mSr Ow rsmyFA jmhwryp mSr AlErbyp، dwlp Erbyp tqE fy OqSY Al$mAl Al$rqy mn qArp OfryqyA، wtqE OyDAa fy OqSY Aljnwb Algrby mn qArp OsyA yHdhA mn Al$mAl AlsAHl Aljnwby Al$rqy llbHr AlmtwsT wmn Al$rq AlsAHl Al$mAly Algrby llbHr AlOHmr wmsAHthA 1,002,450 kylwmtr mrbE. mSr dwlp tqE mEZm OrADyhA fy OfryqyA gyr On jz'A mn OrADyhA، why $bh jzyrp synA'، yqE fy qArp |syA، fhy dwlp EAbrp llqArAt. t$trk mSr bHdwd mn Algrb mE lybyA، wmn Aljnwb mE AlswdAn، wmn Al$mAl Al$rqy mE IsrA}yl wqTAE gzp، wtTl ElY AlbHr AlOHmr mn Aljhp Al$rqyp.
Use the class "Transliteration" to get available transliteration encodings. e.g: to use the buckwalter encoding, call
Transliteration.BUCKWALTER
Example2: Get an Arabic text from a Buckwalter transliteration:
package safar.util;
import common.constants.Transliteration;
import safar.modern_standard_arabic.util.transliteration.impl.SAFARTransliterator;
public class TransliterationTest {
public static void main(final String[] args) {
// Transliterated text to be transformed to Arabic
String transliteration = "mSr Ow rsmyFA jmhwryp mSr AlErbyp، dwlp Erbyp "
+ "tqE fy OqSY Al$mAl Al$rqy mn qArp OfryqyA، wtqE OyDAa fy OqSY "
+ "Aljnwb Algrby mn qArp OsyA yHdhA mn Al$mAl AlsAHl Aljnwby Al$rqy "
+ "llbHr AlmtwsT wmn Al$rq AlsAHl Al$mAly Algrby llbHr AlOHmr wmsAHthA "
+ "1,002,450 kylwmtr mrbE. mSr dwlp tqE mEZm OrADyhA fy OfryqyA gyr On "
+ "jz'A mn OrADyhA، why $bh jzyrp synA'، yqE fy qArp |syA، fhy dwlp EAbrp "
+ "llqArAt. t$trk mSr bHdwd mn Algrb mE lybyA، wmn Aljnwb mE AlswdAn، wmn "
+ "Al$mAl Al$rqy mE IsrA}yl wqTAE gzp، wtTl ElY AlbHr AlOHmr mn Aljhp Al$rqyp. ";
// Get SAFAR transliterator
SAFARTransliterator transliterator = new SAFARTransliterator();
// Transform the transliterated text to Arabic according to the backwalter encoding
String arabicText = transliterator.transliterateLatinToArabic(transliteration, Transliteration.BUCKWALTER);
// Print the result of transliteration
System.out.println(arabicText);
}
}
The result of this transformation is:
مصر أو رسميًا جمهورية مصر العربية، دولة عربية تقع في أقصى الشمال الشرقي من قارة أفريقيا، وتقع أيضاَ في أقصى الجنوب الغربي من قارة أسيا يحدها من الشمال الساحل الجنوبي الشرقي للبحر المتوسط ومن الشرق الساحل الشمالي الغربي للبحر الأحمر ومساحتها 1,002,450 كيلومتر مربع. مصر دولة تقع معظم أراضيها في أفريقيا غير أن جزءا من أراضيها، وهي شبه جزيرة سيناء، يقع في قارة آسيا، فهي دولة عابرة للقارات. تشترك مصر بحدود من الغرب مع ليبيا، ومن الجنوب مع السودان، ومن الشمال الشرقي مع إسرائيل وقطاع غزة، وتطل على البحر الأحمر من الجهة الشرقية.
If you deal with Files as input instead of Strings or if you want to save results as file, you can call other overloaded methods to cover more possibilities. Here is the complete list of all overloaded methods concerning transliteration:Transliterate Arabic to Latin:
Methods that save result as XML File:
void transliterateArabicToLatin(String inputText, String transliterationEncoding, File outputFile);
void transliterateArabicToLatin(File inputFile, String inputEncoding, String transliterationEncoding, File outputFile);
Methods that return result as String:
String transliterateArabicToLatin(String inputText, String transliterationEncoding);
String transliterateArabicToLatin(File inputFile, String inputEncoding, String transliterationEncoding);
Transliterate Latin to Arabic:
Methods that save result as XML File:
void transliterateLatinToArabic(String inputText, String transliterationEncoding, File outputFile);
void transliterateLatinToArabic(File inputFile, String inputEncoding, String transliterationEncoding, File outputFile);
Methods that return result as String:
String transliterateLatinToArabic(String inputText, String transliterationEncoding);
String transliterateLatinToArabic(File inputFile, String inputEncoding, String transliterationEncoding);
Where:
| inputText | The text to be transliterated/inversed |
| inputFile | The File to be transliterated/inversed |
| outputFile | The File in which results will be saved |
| inputEncoding | The encoding of the inputFile. If not specified, UTF-8 will be used by default. Use the class Encoding to get all available encodings. e.g: to use UTF-8, call Encoding.UTF_8 |
| transliterationEncoding | The transliteration encoding used to transliterate (or inverse transliteration) a text. Use the class "Transliteration" to get all available encodings. e.g: to use Buckwalter transliteration, call Transliteration.BUCKWALTER |
4.5 Benchmark
4.5.1 Morphological analysers
The main purpose of the Benchmark is to compare results returned by morphological analyzers implementations using known annotated corpora. This operation gives an idea about the relevance of the results according to the selected corpus.
Example1: compare BAMA analysis results using Sawalha corpus (Gold Standard of Arabic: Quranic text Chapter 29) based on stem, prefix, suffix, POS and lemma:
package safar.util;
import common.constants.Analyzer;
import common.constants.Corpus;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerBenchmark;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerMetrics;
public class BenchmarkTests {
public static void main(final String[] agrs) {
// Compares one morphological analyzer using an evaluation coprus.
// Execute the Benchmark and get results as MorphologyAnalyzerMetrics object
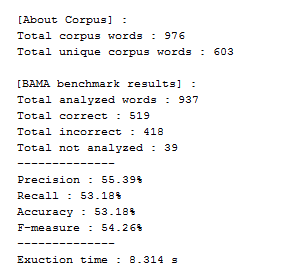
MorphologyAnalyzerMetrics metric = MorphologyAnalyzerBenchmark.compare(Analyzer.ALKHALIL, Corpus.SAWALHA);
// Print results of the benchmark
System.out.println("\n");
System.out.println("[" + metric.getImplemantationName() + " benchmark results] :");
System.out.println("Total corpus words : " + metric.getTotalCorpusWords());
System.out.println("Exuction time : " + metric.getExecutionTime() + " s");
System.out.println("--------------");
System.out.println("Precision: " + metric.getPrecision());
System.out.println("Recall: " + metric.getRecall());
System.out.println("Accuracy: " + metric.getAccuracy());
System.out.println("F-measure: " + metric.getFMeasure());
System.out.println("Richness: " + metric.getGlobalRichness());
System.out.println("---------------------\n");
System.out.println("GM-Score: " + metric.getGmScore());
}
}
- Use the class "Analyzer" to get available analyzers names. e.g: to compare Alkhalil, use
Analyzer.BAMA instead of Analyzer.Alkhalil- Use the class "Corpus" to get available evaluation corpus names. e.g: to use Sawalha evaluation corpus, call
Corpus.SAWALHA
Example of results:
You have also the possibility to compare multiple implementations results at the same time using the same evaluation corpus. This operation returns a list of MorphologyAnalyzerMetrics that you can manipulate easily:
package safar.util;
import common.constants.Analyzer;
import common.constants.Corpus;
import java.util.ArrayList;
import java.util.List;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerBenchmark;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerMetrics;
public class BenchmarkTests {
public static void main(final String[] agrs) {
// Compare a list of morphological analysers using an avaluation coprus
// Prepare the list of morphological analyzers
List listAnalyzersImplNames = new ArrayList();
listAnalyzersImplNames.add(Analyzer.BAMA);
listAnalyzersImplNames.add(Analyzer.ALKHALIL);
// Compare the list of analysers using an avaluation coprus
List metrics = MorphologyAnalyzerBenchmark.compare(listAnalyzersImplNames, Corpus.SAWALHA);
// Print the results of benchmark
for (MorphologyAnalyzerMetrics metric : metrics) {
System.out.println("\n");
System.out.println("[" + metric.getImplemantationName() + " benchmark results] :");
System.out.println("Total corpus words : " + metric.getTotalCorpusWords());
System.out.println("Exuction time : " + metric.getExecutionTime() + " s");
System.out.println("--------------");
System.out.println("Precision: " + metric.getPrecision());
System.out.println("Recall: " + metric.getRecall());
System.out.println("Accuracy: " + metric.getAccuracy());
System.out.println("F-measure: " + metric.getFMeasure());
System.out.println("Richness: " + metric.getGlobalRichness());
System.out.println("---------------------\n");
System.out.println("GM-Score: " + metric.getGmScore());
}
}
}
4.5.2 Stemmers
The main purpose of the Benchmark is to compare results returned by stemmers using known annotated corpora. This operation gives an idea about the relevance of the results according to the selected corpus.
Example1: compare MOTAZ and LIGHT10 using NAFIS corpus:
package safar.util;
import common.constants.Analyzer;
import common.constants.Corpus;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerBenchmark;
import safar.modern_standard_arabic.util.benchmark.morphology.analyzer.MorphologyAnalyzerMetrics;
public class BenchmarkTests {
public static void main(final String[] agrs) {
// prepare the list of stemmers
List listStemmersImplNames = new ArrayList();
listStemmersImplNames.add(Stemmer.MOTAZ_STEMMER);
listStemmersImplNames.add(Stemmer.LIGHT10_STEMMER);
//compare the list of stemmers using NAFIS evaluation coprus
List list = StemmerBenchmark.compare(listStemmersImplNames, Corpus.NAFIS, "stem");
//print the results of benchmark
for (int i = 0; i < list.size(); i++) {
StemmerMetrics metric = list.get(i);
System.out.println("\n");
System.out.println("[" + metric.getImplemantationName() + " benchmark results] :");
System.out.println("Total corpus words : " + metric.getTotalCorpusWords());
System.out.println("Total Stemmer words : " + metric.getTotalStemmerWords());
System.out.println("-----");
System.out.println("Total Correct stems: " + metric.getTotalCorrectStems());
System.out.println("Total Incorrect stems : " + metric.getTotalIncorrectStems());
System.out.println("Total Stemmer Unique Stems : " + metric.getTotalStemmerUniqueStems());
System.out.println("Total Stemmer Words Not Changed : " + metric.getTotalStemmerWordsNotChanged());
System.out.println("Total Removed Characters : " + metric.getTotalRemovedCharacters());
System.out.println("-----");
System.out.println("Precision : " + metric.getPrecision());
System.out.println("Accuracy : " + metric.getAccuracy());
System.out.println("WCC : " + metric.getWcc());
System.out.println("ICF : " + metric.getIcf());
System.out.println("WCA : " + metric.getWca());
System.out.println("ARC : " + metric.getArc());
System.out.println("-----");
System.out.println("Execution time : " + metric.getExecutionTime());
System.out.println("Gs-Score : " + metric.getgScore());
}
}
}
Example of results:
[MOTAZ STEMMER benchmark results] : Total corpus words : 139 Total Stemmer words : 139 ----- Total Correct stems: 43 Total Incorrect stems : 96 Total Stemmer Unique Stems : 134 Total Stemmer Words Not Changed : 35 Total Removed Characters : 152 ----- Precision : 30.9353 Accuracy : 30.9353 WCC : 1.0373 ICF : 3.5971 WCA : 74.8201 ARC : 1.0935 ----- Execution time : 0.04 Gs-Score : 0.0013 [LIGHT10 benchmark results] : Total corpus words : 139 Total Stemmer words : 139 ----- Total Correct stems: 36 Total Incorrect stems : 103 Total Stemmer Unique Stems : 129 Total Stemmer Words Not Changed : 20 Total Removed Characters : 226 ----- Precision : 25.8993 Accuracy : 25.8993 WCC : 1.0775 ICF : 7.1942 WCA : 85.6115 ARC : 1.6259 ----- Execution time : 0.027 Gs-Score : 0.001
4.6 Stop-Words
The Stop-Words tool is composed by two Stop-Words detectors, a rule based SWs detector and a statistics based SWs detector. The statistics based SWs detector uses a classification and a vector space models to detect Domain-Independant and Domain-dependant Stop-Words contained in a corpus. While, the rule based SWs detector is based on a static list to detect and / or remove Domain-Independant Stop-Words contained in a corpus or a string.
Example1: get Domain-Dependant Stop-Words from a corpus
package safar.util;
import safar.modern_standard_arabic.util.stop_words.interfaces.ISWsService;
import safar.modern_standard_arabic.util.stop_words.factory.StopWordFactory;
import java.util.List;
public class CDDSWtest {
public static void main (String[] args) {
// Get implementation from factory
ISWsService sWFactory = StopWordFactory.getSWsImplementation();
// Get Domain-Dependant Stop-Words from a corpus
List sWLst = sWFactory.getDomainDependantStopWords(path);
// print the list
sWLst.forEach((sW) -> {
System.out.println(sW);
});
}
}
Results example form a corpus dealing with the sports field :
فريق الرياضة القدم الموسم الدوري اللاعب كأس كرة الجولة النادي المباراة المنتخب البطولة المدرب اتحاد هدف الجامعة الأبطال لقب
Example2: remove Domain-Independant Stop-Words from a string
package safar.util;
import safar.modern_standard_arabic.util.stop_words.interfaces.ISWsService;
import safar.modern_standard_arabic.util.stop_words.factory.StopWordFactory;
import java.util.List;
public class CDDSWtest {
public static void main (String[] args) {
// Get implementation from factory
ISWsService sWFactory = StopWordFactory.getSWsImplementation();
// Get Domain-Dependant Stop-Words from a corpus
String cleanedTxt = sWFactory.removeDomainIndependantStopWordsFromString("تطلب الاشتراك في "
+" إحدى الخدمات التي يقدمها الموقع، مثل البريد"
+" الالكتروني أو التسجيل في خدمة سؤال وجواب أو المشاركة في "
+" الاختبارات المتاحة، فقد نطلب تقديم بيانات شخصية، مثل الاسم"
+" وعنوان البريد الالكتروني وتاريخ الميلاد. يستخدم الموقع أيضا"
+" ملفات تعريف الارتباط cookies، وهي عبارة عن بيانات محدودة عن "
+" تفضيلات المستخدمين المرتبطيم، وهذه البيانات تساعد الموقع على"
+" تلبية احتياجات مستخدميها. بشكل مشابه يقوم موقع الموقع أيضا "
+" بتسجيل عنوان الـ IP، وهو عبارة عن رقم يمكن أن يحدد كل جهاز "
+" كمبيوتر يستخدم شبكة الانترنت. نستخدم برامج تحليلية لمتابعة "
+" ملفات الارتباط cookies وعناوين الـ IP بهدف التعرف على احتياجات"
+" المستخدمين. ولا تستخدم هذه المعلومات لتجميع ملفات شخصية عنكم. ");
// print the cleaned text
System.out.println(cleanedTxt);
}
}
Results :
تطلب الاشتراك إحدى الخدمات يقدمها الموقع، البريد الالكتروني التسجيل خدمة سؤال وجواب المشاركة الاختبارات المتاحة،
نطلب تقديم بيانات شخصية، الاسم وعنوان البريد الالكتروني وتاريخ الميلاد. يستخدم الموقع أيضا ملفات تعريف الارتباط cookies،
عبارة بيانات محدودة تفضيلات المستخدمين المرتبطيم، البيانات تساعد الموقع تلبية احتياجات مستخدميها. بشكل مشابه يقوم موقع
الموقع أيضا بتسجيل عنوان الـ IP، عبارة رقم يمكن يحدد جهاز كمبيوتر يستخدم شبكة الانترنت. نستخدم برامج تحليلية لمتابعة
ملفات الارتباط cookies وعناوين الـ IP بهدف التعرف احتياجات المستخدمين. تستخدم المعلومات لتجميع ملفات شخصية عنكم.
4.7 Pattern Detection
The pattern detection tool will detect the pattern of the input text.
Example:
package safar.util;
import safar.modern_standard_arabic.util.patternDetection.factory.PatternFactory;
import safar.modern_standard_arabic.util.patternDetection.interfaces.IPattern;
import safar.modern_standard_arabic.util.patternDetection.model.ArabicPattern;
public class PatternDetection {
public static void main (String[] args) {
String word= "مُنَّمِسٌ";
// Factory instantiation and method call
IPattern pattern= PatternFactory.getSAFARPatternImplementation();
ArabicPattern wordPatterned = pattern.detectPattern(word);
// Output the result
System.out.println(wordPatterned.toString());
}
}
Result:
مُنَّمِسٌ As Noun : مُفَّعِلٌ As Verb : فَعْلَلَ-يُفَعْلِلُ
5. Resources
These examples illustrate the use of SAFAR resources APIs.
5.1 Alphabets lexicon
The alphabet resource (الأَبْجَدِيَّة العَرَبِيَّة الحُرُوف) is the Arabic script written from right to left, constituted by consonants (letters in resource nomenclature), vowels and punctuation marks.
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.alphabet.factory.AlphabetFactory; import safar.modern_standard_arabic.resources.lexicon.alphabet.interfaces.IAlphabetService; import safar.modern_standard_arabic.resources.lexicon.alphabet.model.Letter; import safar.modern_standard_arabic.resources.lexicon.alphabet.model.Punctuation; import safar.modern_standard_arabic.resources.lexicon.alphabet.model.Vowel; public class AlphabetTest { public static void main (String[] args) { // Letter variable declaration Letter letter; // Get alphabet implementation from factory IAlphabetService alphabetFactory = AlphabetFactory.getAlphabetImplementation(); // Get all alphabets from data file Listlexicon = alphabetFactory.getLetters(); // print alphabets for (Letter le:lexicon) { System.out.println(le.toString()); } // Get a specific letter letter = alphabetFactory.getLetter("م"); System.out.println(letter.toString()); // Get all vowels from data file List vLexicon = alphabetFactory.getVowels(); for (Vowel vowel:vLexicon) { System.out.println(vowel.toString()); } } }
Example of results:
description arabic طاء english TAH display isolated ط end ـط middle ـطـ begining طـ code unicode U+0637 translit buckwalter T wiki .t
5.2 Clitics lexicon
In Arabic, clitics are attached to a stem (before the stem for “proclitics” and after the stem for “enclitics”) or to each other without any orthographic mark. The Clitics resource in SAFAR consists of a set of proclitic-enclitic couple.
Example1: Get all clitics from data file
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.clitics.factory.CliticFactory; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.ICliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.IEncliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.IProcliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.model.Clitic; public class CliticsTest { public static void main (String[] args) { // clitic variable declaration Clitic clitic; // Get clitics implementation from factory IAlphabetService alphabetFactory = AlphabetFactory.getAlphabetImplementation(); // Get all clitics from data file Listclitics = cliticFactory.getAllClitics(); // print clitics for (Clitic cl:clitics) { System.out.println(cl.toString()); } } }
Example of results:
أَفَلَ - نَا أَوَلَ - كُنَّهُنّ أَفَ - كُمُوهُمْ لَ - كُمُوهَا - هَا
Example2: Test if a specific couple is a clitic or not
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.clitics.factory.CliticFactory; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.ICliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.IEncliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.interfaces.IProcliticService; import safar.modern_standard_arabic.resources.lexicon.clitics.model.Clitic; public class CliticsTest { public static void main (String[] args) { // clitic variable declaration Clitic clitic; // Get clitics implementation from factory IAlphabetService alphabetFactory = AlphabetFactory.getAlphabetImplementation(); // Test if a specific couple is a clitic or not Boolean exist = cliticFactory.isClitic("هل","سي"); if (exist) { System.out.println("is clitic"); } else { System.out.println("not a clitic"); } } }
Results:
not a clitic
5.3 Particles lexicon
Arabic words are divided into three categories: noun, verb and particle. Particles are words to which noun and verb symptoms cannot apply. They are divided into two categories: building particles (حروف المباني) and meaning particles(حروف المعاني). The particles data in SAFAR are designed by the collection of Arabic particles with their morphosyntactic features
Example1: Get all Particles from data file
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.factory.NativeParticleFactory; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.interfaces.INativeParticleService; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.Complement; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.MClass; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.Particle; public class ParticlesTest { public static void main (String[] args) { // Particle variable declaration Particle theParticle; // Morphological Class variable declaration MClass mclass; // Complement variable declaration Complement complement; // Get Particles implementation from factory INativeParticleService particleFactory = NativeParticleFactory.getParticleImplementation(); // Get all Particles from data file ListtheParticles = particleFactory.getParticles(); for (Particle part:theParticles) { List mclasses = part.getMClasses(); for (MClass mc:mclasses) { List complements = mc.getComplements(); for (Complement cmp:complements) { System.out.println(part.getVoweledform() + "\t" + mc.getMdesc() + "\t" + cmp.getCdesc()); } } } } }
Example of results:
يَا حرف نداء للقريب و البعيد و للندبة لَكِنَّ ناسخ حرفي يفيد الاستدراك مَتَى حرف جر بمعنى من إذَا حرف المفاجأة يفيد المفاجأة إذَا حرف شرط ظرفية متضمنة معنى الشرط
Example2: Get all Particles from data file of a specifc class
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.factory.NativeParticleFactory; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.interfaces.INativeParticleService; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.Complement; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.MClass; import safar.modern_standard_arabic.resources.lexicon.particles.native_particles.model.Particle; public class ParticlesTest { public static void main (String[] args) { // Particle variable declaration Particle theParticle; // Morphological Class variable declaration MClass mclass; // Complement variable declaration Complement complement; // Get Particles implementation from factory INativeParticleService particleFactory = NativeParticleFactory.getParticleImplementation(); // Get all Particles from data file of a specifc class Listparticles = particleFactory.getParticleByMClass("حرف جر"); for (String myParticle : particles) { System.out.println(myParticle); } } }
Example of results:
إلى حاشا حتى خلا رب عدا على عن
5.4 CALEM lexicon
Comprehensive Arabic LEMmas (CALEM "translated in Arabic as a words collection") lexicon is a collection of stem/lemma pairs contaning 164,272 lemmas representing 7,133,106 stems.
Example1: Get all Stems from data file
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.factory.StemLemmaFactory; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.interfaces.IStemLemmaService; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.model.Stem; public class StemsTest { public static void main (String[] args) { // Get StemLemma implementation from factory IStemLemmaService sLFactory= StemLemmaFactory.getStemLemmaImplementation(); // Get all Stems from data file
// We can get Lemmas instead of Stems by calling the getLems() method instead of getStems() ListtheStems = sLFactory.getStems(); for (Stem theStem:theStems) { System.out.println(theStem.getUnvStem()); } } }
result extract:
Example2: Get all possible lemmas of the input Stems
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.factory.StemLemmaFactory; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.interfaces.IStemLemmaService; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.calem.model.StemLemmas; public class StemsTest { public static void main (String[] args) { // Get StemLemma implementation from factory IStemLemmaService sLFactory= StemLemmaFactory.getStemLemmaImplementation(); // Get all possible lemmas of the input Stems Liststemslemmas= sLFactory.getStemsLemmas(Arrays.asList("مالك", "أالك", "إالك", "إال", "أال", "مال")); for (StemLemmas sLs:stemslemmas) { System.out.println(sLs.getStem() + "" + "\t" + sLs.getLemmas().toString()); } } }
results:
مالك [مَالَكَ, مَالِكٌ] مال [مَالٍ, مَالَ, مَالٌّ]
5.5 Contemporary dictionary
The Contemporary Arabic Language dictionary is a general semasiological monolingual dictionary written by Ahmed Mukhtar Abdul Hamid with the help of a working group, offering entries information distributed among several morphological and semantic information.
Example1: Get a Lexical Entries by lemma
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.dictionnary.factory.DictFactory; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.dictionnary.interfaces.IDictService; import safar.modern_standard_arabic.modern_standard_arabic.resources.lexicon.dictionnary.model.LexicalEntry; public class ContemporaryTest { public static void main (String[] args) { // Get Moassir implementation from factory IDictService contDictFactory = DictFactory.getMoassirImplementation(); // get LexicalEntries by unvoweled lemma ListlEs = contDictFactory.getLexicalEntriesByUnvoweledLemma("كتب"); // if the LexicalEntries is not empty, loop and display the LexicalEntries string if (!lEs.isEmpty()) { for (LexicalEntry lE: lEs) { System.out.println(lE.toString()); } } else { System.out.println(" No results "); } } }
Results:
كتَبَ: ك ت ب فعل null كتَبَ/ كتَبَ إلى/ كتَبَ في/ كتَبَ لـ يَكتُب، كِتابةً وكِتَابًا وكَتْبًا، فهو كاتب، والمفعول مَكْتوب (للمتعدِّي) كتَّبَ: ك ت ب فعل null كتَّبَ يكتِّب، تَكْتِيبًا، فهو مُكتِّب، والمفعول مُكتَّب كَتْب: ك ت ب مفرد null مصدر كتَبَ/ كتَبَ إلى/ كتَبَ في/ كتَبَ لـ.Example2: Get lexical entries by root
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.dictionnary.factory.DictFactory; import safar.modern_standard_arabic.resources.lexicon.dictionnary.interfaces.IDictService; import safar.modern_standard_arabic.resources.lexicon.dictionnary.model.LexicalEntry; public class ContemporaryTest { public static void main (String[] args) { // Get Moassir implementation from factory IDictService contDictFactory = DictFactory.getMoassirImplementation(); // get LexicalEntries by root ListlEs = contDictFactory.getLexicalEntriesByRoot("أتي"); // if the LexicalEntries is not empty, loop and display the LexicalEntries string if (!lEs.isEmpty()) { for (LexicalEntry lE: lEs) { System.out.println(lE.toString()); } } else { System.out.println(" No results "); } } }
results:
أتَى: أ ت ي فعل null أتَى/ أتَى بـ/ أتَى على يَأتِي، ائْتِ، أَتْيًا وإتْيانًا، فهو آتٍ، والمفعول مَأتيّ (للمتعدِّي) أُتيَ: أ ت ي فعل null أُتيَ/ أُتيَ بـ/ أُتيَ من يُؤْتَى، أَتْيًا وإِتيانًا ومَأْتًى ومَأْتاةً، والمفعول مَأْتيّ آتى: أ ت ي فعل null آتى1 يُؤتي، آتِ، إيتاءً، فهو مُؤْتٍ، والمفعول مُؤْتًى آتى: أ ت ي فعل null آتى2 يؤاتي، آتِ، مُؤاتاةً، فهو مُؤاتٍ، والمفعول مُؤاتًى تأتَّى: أ ت ي فعل null تأتَّى عن/ تأتَّى لـ/ تأتَّى من يتأتَّى، تَأَتَّ، تَأَتّيًا، فهو مُتأتٍّ، والمفعول مُتأتًّى عنه آتٍ: أ ت ي مفرد null null أَتْي: أ ت ي مفرد null مصدر أتَى/ أتَى بـ/ أتَى على وأُتيَ/ أُتيَ بـ/ أُتيَ من. إتْيان: أ ت ي مفرد null مصدر أتَى/ أتَى بـ/ أتَى على وأُتيَ/ أُتيَ بـ/ أُتيَ من. إيتاء: أ ت ي مفرد null مصدر آتى1. تأتٍّ: أ ت ي مفرد null مصدر تأتَّى عن/ تأتَّى لـ/ تأتَّى من مُؤاتٍ: أ ت ي مفرد null null مَأْتاة: أ ت ي مفرد null null مَأْتًى: أ ت ي مفرد null null pl:مَآتٍ
5.6 Interactive dictionary
Intermediate Lexicon (المعجم الوسيط) is an Arabic Lexicon version of the Arabic Language Academy in Cairo.
Example1: Get all verbal Lexical Entries
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.dictionnary.factory.DictFactory; import safar.modern_standard_arabic.resources.lexicon.dictionnary.interfaces.IDictService; import safar.modern_standard_arabic.resources.lexicon.dictionnary.model.LexicalEntry; public class InteractiveTest { public static void main (String[] args) { // Get Wassit implementation from factory IDictService wassitDictFactory = DictFactory.getWassitImplementation(); // get LexicalEntries by POS ListlEs = wassitDictFactory.getLexicalEntriesByPOS("فعل"); // if the LexicalEntries is not empty, loop and display the LexicalEntries string if (!lEs.isEmpty()) { for (LexicalEntry lE: lEs) { System.out.println(lE.getLemma()); } } else { System.out.println(" No results "); } } }
Result extract:
تَثَفَّل جَثَم أَجْكَر تَجَوَّل حَبَّ احْتَجّ حَدّ حَظَل حَفِظ تَحَلَّم احْمَرّ حَوَّد تَحَيَّر تَحَيَّز حَاص خَنْدَف رَعِف تَزَخْرَف اسَّاقَط شَظِف شَنِئ اصَّبَر
Example2: Test if a specific word is a Noun or not
// Your package here package safar_test; import java.util.List; import safar.modern_standard_arabic.resources.lexicon.dictionnary.factory.DictFactory; import safar.modern_standard_arabic.resources.lexicon.dictionnary.interfaces.IDictService; import safar.modern_standard_arabic.resources.lexicon.dictionnary.model.LexicalEntry; public class InteractiveTest { public static void main (String[] args) { // Get Wassit implementation from factory IDictService wassitDictFactory = DictFactory.getWassitImplementation(); // get the boolean relative to the noun Boolean exist = wassitDictFactory.isNoun("زوع"); if (exist) { System.out.println("زوع is a noun"); } else { System.out.println("زوع isn't a noun"); } }
Results:
زوع is a noun
1.2 MADED lexicon
The Contemporary Arabic Language dictionary is a general semasiological monolingual dictionary written by Ahmed Mukhtar Abdul Hamid with the help of a working group, offering entries information distributed among several morphological and semantic information.
Example1: Get a Lexical Entries by lemma
// Your package here package safar_test; import java.util.List; import safar.moroccan_arabic.resources.lexicon.maded.factory.CorpusLidFactory; import safar.moroccan_arabic.resources.lexicon.maded.model.LexicalEntry; import safar.moroccan_arabic.resources.lexicon.maded.interfaces.ILidCorpusService; public class MdedTest { public static void main (String[] args) { // Get MADED implementation from the factory and call the method ILidCorpusService MdedDictFactory = CorpusLidFactory.getMADEDImplementation(); // get LexicalEntries by unvoweled lemma ListLEs = MdedDictFactory.getLexicalEntriesByUnvoweledLemma(lemma); // if the lexicalEntries is not empty, loop and display the entries if (LEs!= null) { System.out.println("\n" + LEs.size() + " Entries for the lemma:" + lemma + "\n"); System.out.println("-----------------------------------------------------------"); System.out.println("Lemma"+ "\t"+ " MSA" +"\t"+ "POS"+ "\t"+ "Root"+ "\t"+ "Origin"); System.out.println("-----------------------------------------------------------"); for (LexicalEntry lE:LEs) { System.out.println(lE.getLemma()+ " \t " + lE.getMsa() + " \t " + lE.getType() + "\t" + lE.getRoot() + "\t" + lE.getOrigin()); } } else { System.out.println("No result"); } } }
Results:
2 Entries for the lemma:شاف ----------------------------------------------------------- Lemma MSA POS Root Origin ----------------------------------------------------------- شاف رأى Verb شاف Arabic شاف رئيس Noun شاف French
1.2 Moralex lexicon
The Contemporary Arabic Language dictionary is a general semasiological monolingual dictionary written by Ahmed Mukhtar Abdul Hamid with the help of a working group, offering entries information distributed among several morphological and semantic information.
Example1: Get a Lexical Entries by lemma
// Your package here package safar_test; import java.util.List; import safar.moroccan_arabic.resources.lexicon.moralex.factory.Moralex; import safar.moroccan_arabic.resources.lexicon.moralex.model.LexicalEntry; import safar.moroccan_arabic.resources.lexicon.moralex.interfaces.IMoralexService; public class MoralexTest { public static void main (String[] args) { // Get moralex implementation from factory IMoralexService MDictFactory = Moralex.getmoralexImplementation(); // get LexicalEntries by unvoweled lemma ListLE = MDictFactory.getLexicalEntriesByPOS("verb"); // if the LexicalEntries is not empty, loop and display the LexicalEntries string if (LE!= null) { System.out.println(LE.get(0).getMorpheme()); System.out.println(LE.toString()); } else { System.out.println(" No results "); } } }
Results:
كات [p_kat_25 prefix verb affirmative 2 all s كات, p_to_psv_21 proclitic+prefix verb affirmative 2 all all كاتّ, p_kat_25b prefix verb affirmative 3 f s كات, p_to_psv_25 proclitic+prefix verb affirmative 3 f s كاتّ, p_kat_25c prefix verb affirmative 2 all p كات, p_kat_67 prefix verb affirmative 2 all s تات, p_kat_67b prefix verb affirmative 3 f s تات, p_kat_67c prefix verb affirmative 2 all p تات, p_kay_18 prefix verb affirmative 3 m s كاي, p_to_psv_5 proclitic+prefix verb affirmative 3 all p كايت, ... affirmative 2 f s يها, s_y_727 suffix+enclitic verb negative 2 f s يهاش, s_y_729 suffix+enclitic verb affirmative 2 f s يهم, s_y_7299 suffix+enclitic verb negative 2 f s يهمش, s_y_721 suffix+enclitic verb affirmative 2 f s ينا, s_y_722 suffix+enclitic verb negative 2 f s يناش, s_y_723 suffix+enclitic verb affirmative 2 f s يني, s_y_724 suffix+enclitic verb negative 2 f s ينيش, s_y_725 suffix+enclitic verb affirmative 2 f s يه, s_y_728 suffix+enclitic verb negative 2 f s يهش, s_y_73imp suffix verb affirmative 2 f s ي, s_y_726imp suffix+enclitic verb affirmative 2 f s يها, s_y_729imp suffix+enclitic verb affirmative 2 f s يهم, s_y_721imp suffix+enclitic verb affirmative 2 f s ينا, s_y_723imp suffix+enclitic verb affirmative 2 f s يني, s_y_725imp suffix+enclitic verb affirmative 2 f s يه]