[New] SAFAR V3 has been released.
[New] This project is open to your contributions. Everyone can contribute in its development.
SAFAR is a platform dedicated to ANLP (Arabic Natural Language Processing). It is open source, cross-platform, modular, and provides an integrated development environment (IDE). It includes :
» Resources needed for different treatments ANLP
» Basic levels modules of language, especially those of the Arabic language, namely morphology, syntax and semantics
» Applications for the ANLP
NB: All integrated tools and resources remain under the copyright of their original authors. More details.
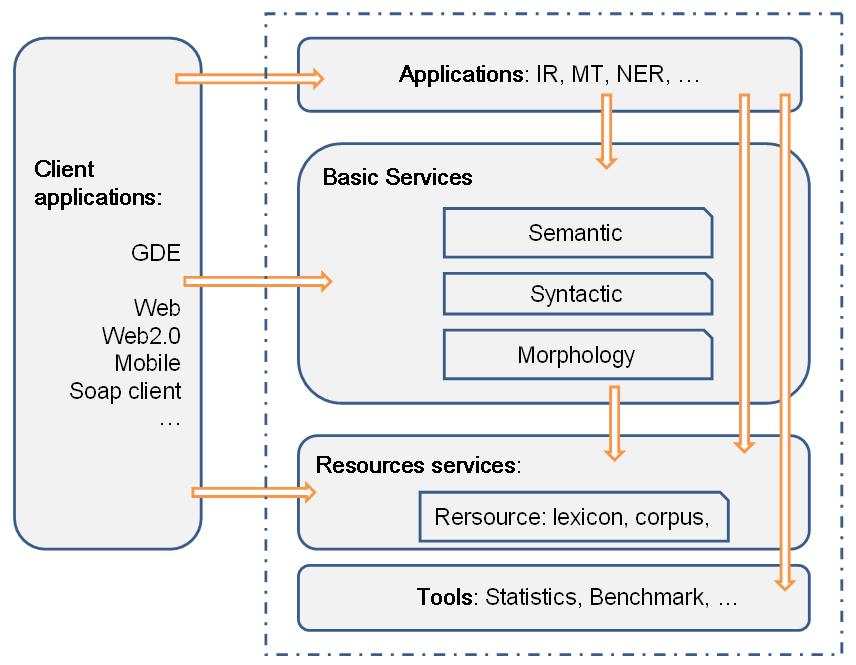
General architecture of SAFAR
 |
|
Each layer is developed as a set of reusable Java API:
» Tools: includes a range of technical services (statistical functions, test tools, tokenization, sentences splitting etc.)
» Resource Services: Provides resources language consultation such as lexicons and corpora.
» NLP services: Contains three layers of processing language Regular (morphology, syntax and semantics)
» Applications: Contains high-level applications that use layers listed above.
» Client: In case the user needs to directly use services layer.
SAFAR V3 features
The services currently provided by SAFAR V3 and which are ready to be used are:
Modern standard arabic Applications : Key Words Extractor [New] Light Summarizer Moajam Moaassir (MSA lexicon Desktop browser) Moajam Tafaoli (Al wassit lexicon Desktop browser) Morpho-Syntactic Processor Stem Counter Stopwords Analyzer [New] Syntactic parsers : FARASA Pos Tagger [New] SAFAR Light Pos Tagger [New] Stanford Parser FARASA Parser [New] Morphological analyzers : Alkhalil Morphological Analyzer Alkhalil 2 Morphological Analyzer [New] BAMA Morphological Analayzer MADAMIRA Morphological Analayzer Stemmers : ISRI Stemmer Khoja Stemmer Light10 Stemmer Motaz Stemmer SAFAR Stemmer [New] Tashaphyne Stemmer Lemmatizers : Alkhalil Lemmatizer [New] FARASA Lemmatizer [New] SAFAR Lemmatizer [New] Utils : Benchmark for Morphological Analyzers Benchmark for Stemmers [New] Benchmark for Syntactic Parsers [New] Normalization Pattern Detection [New] Sentence splitter Stop Words [New] Tokenization Transliteration Resources: Alphabet Clitics Particles lexicon Al wassit dictionary CALEM (stems/lemmas) lexicon [New] Contemporary dictionary Machine Learning: SAFAR Hidden Markov Model [New] SAFAR Levenshtein distance [New] Weka Lib FT Lib Moroccan Arabic Resources: Maded lexicon [New] Moralex lexicon [New] The following module is removed: Sentence Processor Ontology (AWN and extended AWN)